Hey everyone! We're trying something new for this release, by creating a place for discussion around updates we
push out for Cycle. It's a more discussion oriented version of our changelog, where we can engage with all of you
about what's new.
This release (2025.04.24.02) is a huge release that has been in the works for nearly a month now. It brings with it
a lot of stability and performance improvements, but also tons of feature requests we've received from all of you.
New Stuff
We've added a few new goodies to the platform based on your feedback.
A New Network Telemetry Graph
We've added a new graph to the server dashboard, that shows network traffic transmission on a per network interface basis. It's now possible to see data transmitted over the private network, public network, or even SDNs.
You Can Now Restart a Container
Finally, right? Well, you could always stop and start them, but there was one major issue with this method -
Cycle would restart all of them at once...
With the new "restart" functionality, the platform will respect the stagger set in the container's configuration,
preventing downtime while your restart is in progress.
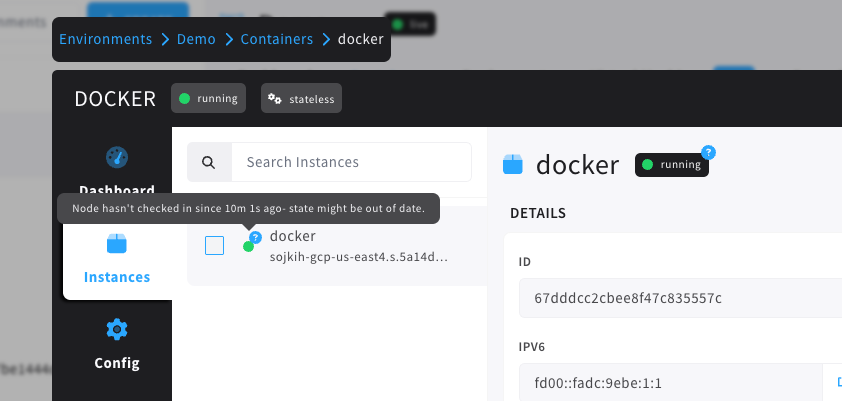
Instance State Uncertainty
Instance states have a 'normal state', such as running, but also have health checks, migration state, traffic draining, and more. One thing we've heard from our users is that sometimes their instance state will
still say 'running', but the server that instance was running on went offline. What gives?
Well, the TL;DR is that we don't actually know that it went offline. Cycle relies on checkins from the underlying
host to know what state that instance is in, and if it misses a checkin, or the network drops, the instance may still
be running, even if Cycle can't prove it.
This led to some uncertainty, but we didn't want to alert people that an instance was offline just because of a network hiccup. In this release, we've tackled the issue by introducing an 'uncertainty' marker on top of container
instances where the underlying host has missed a couple checkins.
Now, you'll be alerted that something may be off about an instance even if we're not sure what state it might be in
anymore. Here's what that looks like:
Server Nicknames
Last but certainly not least, we've added the ability to set a custom name on your servers, that will be visible throughout the interface. It will
appear anywhere a hostname previously did. If no nickname is set, you'll still see the same hostname from before.
(we wouldn't want to hide Michael T's latest server hostname).
Improvements
Along with the new features, we've improved a handful of things as well.
Source IP Routing
We've introduced a new load balancer routing mode, dubbed Source IP. this mode will attempt to provide sticky sessions for all requests coming from a specific IP address.
Better SFTP Lockdown Intelligence
Cycle has had SFTP lockdown intelligence for over a year now, but some clients would open up dozens of new connections
when navigating or transferring files, possibly for better throughput. These clients would quickly put the SFTP connection into lockdown, blocking all new connections.
In this release, we've made it smarter - lockdown will not count new connections from a recently authenticated IP address toward the lockdown criteria. Clients can be greedy with new connections, while bad actors still get locked out.
Scoped Variable Files: Users, Groups, and Permissions
We've added support for a UID, GID, and file permissions to be set on scoped variable files that are injected into the container. Some applications require specific permissions on files to play nice, and this alleviates the need for any
funky workarounds that were previously required.
Load Balancer IP Display
Prior to this release, the environment dashboard would show the CIDR (the entire address space) allocated to a load balancer instance. While useful in some circumstances, most people (ourselves included) just wanted to see the specific IP attached to that load balancer instance. Now, when you go to an environment dashboard, you'll see the correct IP.
There were quite a few other minor tweaks and bug fixes, along with a LOT of work on something we'll be revealing very soon. Leave a comment with your thoughts on the latest update, questions you may have, or any issues you run into.
(You can also message any of our team in slack)
Our next release will be historic...you won't want to miss it.